

As computing power and technologies related to infrastructure are advancing – allowing users to handle the larger volume, velocity, and variety of datasets, it has become even more feasible for businesses to analyze unstructured data sources.
When working in healthcare, a lot of relevant information (about making accurate predictions and recommendations) is only available in free-text clinical notes. Much of this data is trapped in free-text documents in unstructured form. This data is necessary in order to make decisions.
Natural language processing service makes it easy to use machine learning to extract relevant medical information from unstructured text. One of the important ways to improve patient care and speed up clinical analysis is by analyzing the relationships that are trapped in the free-form medical text, together with hospital admission notes and a patient ’s anamnesis.
Amazon Web Services (AWS) renders help to comprehend medical records in terms of identifying medical information. When compared to other tools which treat medical data/texts as generic, AWS comprehend understand medical terminology, patient information, dosages, medicine brand, date of service and provides the output in JSON format. This unique feature is provided only by AWS comprehend medical currently. Let’s look at the way we deal with this
 This is our Web App home screen.
This is our Web App home screen.
Choose any file and define the path of that file in the specified box. Here, for a demo purpose I have used google image.
After importing path of image, Click on Analyze
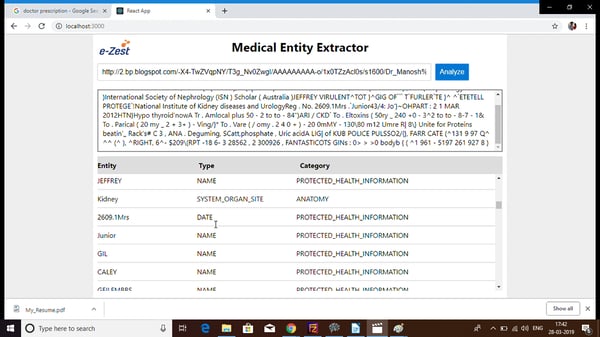
After clicking on Analyze, you will see a well-structured table with all the relevant medical entities extracted from doctor prescription file.
In the case study, we have used Optical Image Recognition and Text Analytics using AWS comprehend medical. Optical Image Recognition is in itself error-prone and can make a lot of errors if information represented in prescription is not clear or in good quality. As this is unstructured data, we have worked a lot in bringing out the right structure to images and documents so that machine learning algorithms can learn better. We encountered issues when identifying medical information – for e.g. whether specific entity extracted is ‘medicine’ or not. Later we used reinforcement learning approach where even if a model makes an error for the first time, it learns from mistakes and when fed well, it starts getting right results in the end.
Today this is achieved by writing and maintaining a set of customized rules using simple text analytics software, which is complicated to build, time-consuming to maintain, and fragile. Machine learning can change all that with models which will dependably perceive the medical data in unstructured text, establish purposeful relationships, and improve over-time.
Using Amazon Comprehend Medical and Azure Computer Vision Service, we have built a solution where we can detect, and extract printed or handwritten text from images and accurately gather information, such as medical condition, medication, dosage, strength, and frequency from a variety of sources like doctors’ notes, clinical trial reports, and patient health records.
Applying reinforcement approach, makes the system understand the medical terms more accurately.
We have done a perfect collaboration between OCR technology and text analytics to extract patient-related information that can be ordered in such a way that we can create a lifetime patient history of each person. This information is very valuable in current industries such as Pharmacy, Legal, Insurance where right information just at fingertips makes a lot of difference.
Tech stack used –AWS comprehend medical API, Azure Computer vision API.






