Why Centralized Log Aggregation:
Logs and Log aggregation is a great topic of interest in all production environments where companies want to have fine grain access to events on their servers.
The increasing count of servers in production deployments makes it necessary to centralize the logs to a central location achieving segregated log streams and advanced level analytics with it.
Apart from investigating the alerts/errors, a trend in logs and visual analytics over the logs of server pool is necessary to make administrators take important and efficient management/ configuration decisions.
Free and open source, scalable logging solutions with advanced analytical capabilities makes Graylog a perfect logging solution.
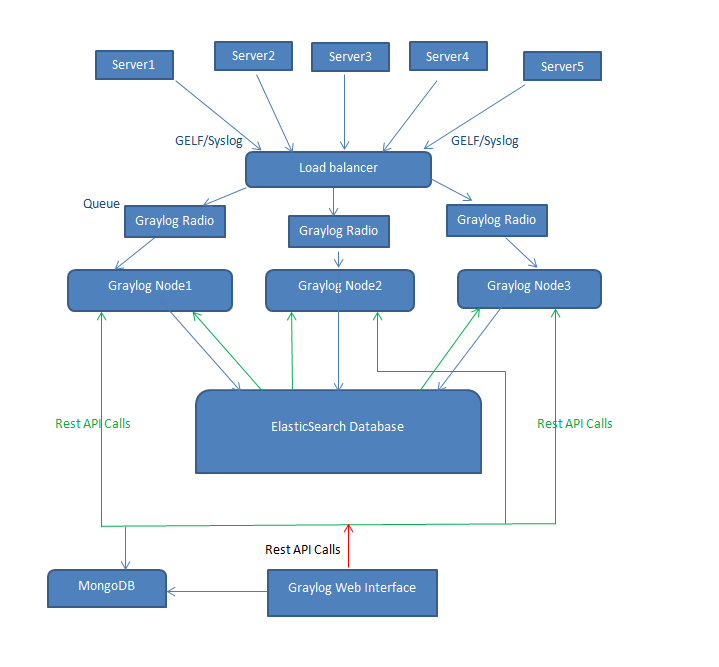
Graylog Configuration Diagram:
Graylog Setup

Technologies and Features:
Graylog App Node
The Graylog App is the core component of the Graylog installation that acts as a centralized logger. The Graylog App logs the incoming logs on the UDP/TCP port into the appropriate elastic search database. Written in Java with advanced analytical capabilities, the core logic is to efficiently use the REST API call of Elastic Search that lies with the Graylog App.
Graylog Web Interface Server:
The Graylog Web Interface Server gives the advanced analytical capabilities to the user to roll, slice and dice their logs to understand performance critical information about the server.
The Web Interface provides capability to segregate the logs into streams depending on the server and topic of interest.
Analyze your Logs over Time Frames

Segregating the logs streams
Security logs Streams, Access Logs Streams, Error logs Streams, Invalid SSH logs streams, Failed Login Attempts Streams, Segregating the streams based on user preference are few examples.
Setting appropriate Alarms and Mails Alerts on preconfigured settings help system administrators keep a remote check on the performance of their server.
Segregating logs based on User Interests and providing read-only access to the interested parties is a great add-on feature of the Graylog Web Interface.

The Web Interface supports Grok based Regex Filter to filter the huge Log database in fraction of seconds.

Elastic Search:
The true power of Graylog to analyze huge database of logs comes due to ElasticSearch. To attain sufficient redundancy the ElasticSearch replicates the nodes and ensures a parallel Graylog node working in case of failure.
The segregation of logs into respective nodes and further shards internally makes ElasticSearch a perfect companion for Graylog.
Mongo DB:
The mongo DB non-relational database works in conjugation with the web interface to store the user data and data of the streams and information about the regex and regular expressions applied for creating the streams.
Ways to get Logs to Graylog
1) Rsyslog over UDP:
Getting your Logs to Graylog Server is highly simplified using Rsyslog Logger:
Adding this one line to /etc/rsyslog.conf works over UDP:
*.* @graylogAppServerIP
2) Graylog using GELF Logger:
GELF Logger is also a standard practice to get your Logs to Graylogs that supports Custom Fields to be included in Logging formats.
Various open source libraries written in PHP, Java, Ruby etc. support this Graylog extended Logging format capability as an add-on.