“The goal is to turn data into information, and information into insight.” - Carly Fiorina
The ultimate goal of every data warehouse is not just to accumulate data but convert it into insights to make effective business decisions which conventional data warehouses and big data solutions struggle to deliver.
On-premise version of many legacy data warehouses fails to meet their fundamental purpose of rapid analytics and derive data-driven insights for business users. These traditional warehouses can’t scale beyond its hardware and result in limited concurrency, poor elasticity, restricted availability and need additional efforts to maintain its security. The legacy data warehouse also requires an additional workforce for maintenance and administrative tasks which adds up to time and resources.
So how to overcome all these on-premise data warehousing issues?
Snowflake is the answer.
The Snowflake data warehouse utilizes and runs on a new SQL database engine with unique architecture designed for the cloud. Snowflake works as an analytic data warehouse provided as Data Warehouse as a Service (DWaaS). Snowflake has many similarities to other enterprise data warehouses but also has additional functionalities and unique capabilities. This modern data warehouse built for the cloud provides a data warehouse that is faster, easier to use, and far more flexible than traditional data warehouse offerings.
Snowflake offers unique capabilities like cloning, data sharing, time travel (Using Time Travel, you can perform actions within a defined period of time), and near real-time data replication incorporated into the data warehouse design and implementation.
Snowflake Architecture:
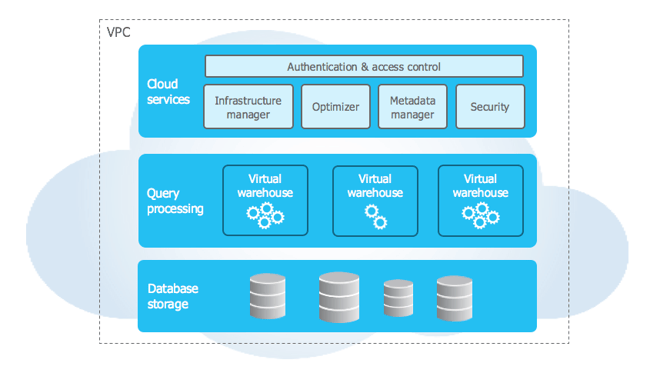
Snowflake’s architecture is a hybrid of traditional shared-disk and shared-nothing database architectures. Snowflake architecture consists of three distinct layers:
- Storage Service Layer
- Execution Compute Layer
- Cloud Service Layer
 Storage Service Layer:
Storage Service Layer:
Snowflake organizes data in logical databases containing one or more schema, each schema contains tables and views. Like standard SQL databases, snowflake stores relational data in table columns using standard SQL datatype. Snowflake tables can also natively store non-relation semi-structured data such as JSON and Avro. Non-relational data is optimized and accessed through SQL just like relational data. Snowflake stores all database data in Amazons S3 cloud storage. As data is loaded into tables, snowflake converts it into optimized columnar compressed encrypted format and stores data in snowflake private S3 buckets.
Execution of compute (Virtual Warehouse Layer)
Queries are executed in snowflake using resources from Amazons EC2 service. Unlike traditional architectures snowflake architecture allows a user to create multiple independent compute clusters called virtual warehouses that all access the same data storage layer without contention or performance degradation. Snowflake handles all aspects of provisioning and configuring compute resources. Users can create virtual warehouses and specify the size of each warehouse. Each virtual warehouse processes query sent to it by users and applications, these virtual warehouses can start processing queries as soon as it provisioned. A virtual warehouse can be scaled up or down at any time without any downtime or disruption. When a user resizes a virtual warehouse, all subsequent queries take advantage of additional resources immediately. Snowflake's distinct cloud architecture enables unlimited scale and concurrency without grappling too much with resource contention.
A virtual warehouse provides the required resources, such as CPU, memory, and temporary storage, to perform the following operations in a Snowflake session:
- Executing SQL SELECT statements that require compute resources (e.g. retrieving rows from tables and views)
- Performing DML operations, such as:
Updating rows in tables (DELETE, INSERT, UPDATE)
Loading data into tables (COPY INTO <table>)
Unloading data from tables (COPY INTO <location>)
Warehouses can be started and stopped at any time. They can also be resized at any time, even while running – to accommodate the need for more or less computing resources based on the type of operations being performed by the warehouse.
Cloud Service Layer:
The cloud service layer is the brain of the system. It is set on the independent higher-level, fault-tolerant services which are collectively responsible for authentication and access control to ensure that only authenticated users can access snowflake services and they will have access only to authorized object for access. Infrastructure manager manages virtual warehouse and coordinates data storage updates and access. Once the transaction is completed all virtual warehouse will see the new version of data with no impact on availability or performance.
Snowflake optimizer has functionality for query parsing, dynamic optimization of queries and auto-tuning to get faster results. These auto-tuned queries speed up querying on both traditional structured data and semi-structured data like JSON, Avro and XML as well.
The services in this layer seamlessly communicate with client applications (including the Snowflake web user interface, JDBC, and ODBC clients) to coordinate query processing and return results. In snowflake, metadata defines warehouse objects and functions as a directory to help locate data warehouse content. It is usually divided into three distinct types or sets: operational, technical, and business data. The service layer retains metadata and the data stored in Snowflake and analyzes how that data has been used, making it possible for new virtual warehouses to immediately use that data. Snowflake cloud service provides industry-leading features that ensure the highest levels of security for your account and users, as well as all the data you store in Snowflake.
Support all of your data in one system
Snowflake delivers on the promise of the cloud data warehouse and allows you to store all of your business data in a single system. That is a sharp contrast from current products which are typically optimized for a single type of data, forcing you to create silos for different data or use cases. Snowflake takes a novel approach by designing a data warehouse that can store and process diverse types of data in a single system without compromising flexibility or performance. Snowflake’s patented approach provides native storage to semi-structured data along with native support to the relational model and the optimizations it can provide.
Native support for semi-structured data
Traditional database architectures were designed to store and process data in strictly relational rows and columns. These architectures build their processing models and optimizations around the assumption that this data consistently contains the set of columns defined by the database schema. This assumption makes performance and storage optimizations like indices and pruning possible but at the cost of a static, costly-to-change data model. Structured, relational data will always be critical for reporting and analysis. But a significant share of data today is machine-generated and delivered in semi-structured data formats such as JSON, Avro, and XML. Semi-structured data like this is commonly hierarchical and rarely adheres to a fixed schema. Data elements may exist in some records but not others, while new elements may appear at any time in any record. Correlating the information in this semi-structured data with structured data is important to extract and analyze the information within it.
Single System for All Business Data
Traditional architectures create isolated silos of data. Structured data is processed in a data warehouse. Semi-structured data is processed with Hadoop. Complex, multi-step operations are required to bring this data together. Scalability limits force organizations to separate workloads and data into separate data warehouses and data marts, essentially creating islands of data that have limited visibility and access to data in other database clusters.
Support all of your use cases elastically
The ideal data warehouse would be able to size up and down on-demand to provide exactly the capacity and performance needed, exactly when it is needed. However, traditional products are difficult and costly to scale up and almost impossible to scale down. That forces an upfront capacity planning exercise that typically results in an oversized data warehouse, optimized for the peak workload but running underutilized at all other times. Cloud infrastructure uniquely enables full elasticity because resources can be added and discarded at any time. That makes it possible to have exactly the resources you need for all users and workloads, but only with an architecture designed to take full advantage of the cloud.
Eliminating Software and Infrastructure Management
The Snowflake data warehouse was designed to eliminate the management of infrastructure. It is built on cloud infrastructure which transparently manages infrastructure for the user. Users simply log in to the Snowflake service and it is immediately available without complex setup required. Ongoing management of the software infrastructure is also managed by Snowflake. Users do not need to manage patches, upgrades, and system security. The Snowflake service automatically manages the system. Capacity planning- a painful requirement during the deployment of a conventional on-premises data warehouse is all but eliminated because Snowflake makes it possible to add and subtract resources on the fly. Because it is easy to scale up and down based on demand and you are not forced into a huge upfront cost while ensuring sufficient capacity for future needs.
Other manual actions within traditional data warehouses that Snowflake automates include:
Continuous data protection
Time Travel enables you to immediately revert any table, database or schema to a previous state. It’s enabled automatically and stores data as it’s transformed for up to 24 hours, or 90 days in enterprise versions.
Copying to clone
Most data warehouses require you to copy data to clone, forcing a large amount of manual effort and significant time investment. Snowflake’s multi-cluster shared data architecture ensures that you never need to copy any data because any warehouse or database automatically references the same centralized data store.
Data distribution
Data distribution is managed automatically by Snowflake based on usage. Rather than relying on a static partitioning scheme based on a distribution algorithm or key chosen by the user at load time, Snowflake automatically manages how data is distributed in the virtual warehouse. Data is automatically redistributed based on usage to minimize data shuffling and maximize performance.
Loading data
Loading data is dramatically simpler because complex ETL data pipelines are no longer needed to prepare data for loading. Snowflake natively supports and optimizes diverse data, both structured and semi-structured, while making that data accessible via SQL.
Dynamic query optimization
Dynamic query optimization ensures Snowflake operates as efficiently as possible by looking at the state of the system when a query is dispatched for execution not just when it is first compiled. That adaptability is a crucial component within Snowflake’s ability to scale up and down.
Scaling compute
Autoscaling is a feature that can be enabled within any Snowflake multi-cluster data warehouse that will match the number of computing clusters to the query or load, without needing manual intervention or input.
Seamless sharing of data
Snowflake’s architecture vastly simplifies the process of sharing data, particularly between different organizations. Instead of needing to manually create copies of data and sending them over FTP, EDI, or cloud file services, Snowflake Data Sharing allows any Snowflake customer to share access to their data with any other Snowflake customer.