This blog is not meant to learn what GIT is or what commands to be used but, this blog can help to organize code in GIT. Structuring code in GIT sometimes becomes a tedious task as the project grows or when multiple teams are involved. In the case of Magento, if using a multi-website instance and individual teams working of respective websites need to work in isolation of the other store but also have to make sure that all stores work in unison. These scenarios can be challenging in how to organize the code, how many branches should be used? How tags should be maintained? Below are two approaches that can be used to organize the code depending on situations choose any and add changes according to what suits best.
Few concepts before moving ahead:
Branch:
Whether a branch is master or smallest feature/bugfix branch it should have a policy and an owner, optionally there should be restricted access to the branch depending upon the importance of the branch.
- Policy: This will define a rule when code can be pushed on to the branch, if the policy is not satisfied then the code should not be pushed or merged into the branch. Example: If it’s a feature branch on which a developer has worked and now this branch has to be merged into the project branch then first it should be verified. If unit tests are complete, coding standards are followed on the development branch and peer review is carried out then only it should be merged. Similarly, before the project branch is merged to Master code review (correct approach, scalability, etc), and testing (performance, regression, etc.) have to be complete.
- Owner: This will be the person responsible to confirm that the policy defined for a branch is being followed.
- Restriction: Optional, so that not every team member can access or modify the branch.
A new branch should only be created if it is not possible to commit changes to any branch without breaking its policy. Following examples can be helpful
Since any work that is not fully tested cannot be pushed to Master, however, a new feature/project branch has to be created.
If a feature is being developed then it cannot be added to the feature/project branch since it is not complete and other people working on that project should not have these changes, a new sub-branch has to be created.
If a hotfix is required then a new branch can be created from the Master branch.
Tags:
Tags are mainly used to create revisions of code, and can also be used for code review if it’s a technical requirement. Since code cannot be pushed to a tag this will be helpful for code reviews and deployment of code if code review successful.
Apart from deployment and code review, we can create tags after main or final deployment of the feature/project branch. It helps in keeping revisions of code and for tracing back bugs if they get introduced in subsequent deployments. Also, they are useful for projects divided into sprints.
For example, if a project is divided into sprints then do not create branches for each sprint. Instead, create a tag after a sprint is finished. Deployments can be planned from the tag and if needed a temporary branch can be created from the same tag.
This will help to keep the number of branches to a minimum.
Let’s move ahead on the structuring of code but keeping the above terms in mind, this will help you to better organize code and to minimize branches if using too many branches then this will lead to confusion at some point in time.
Approach 1:
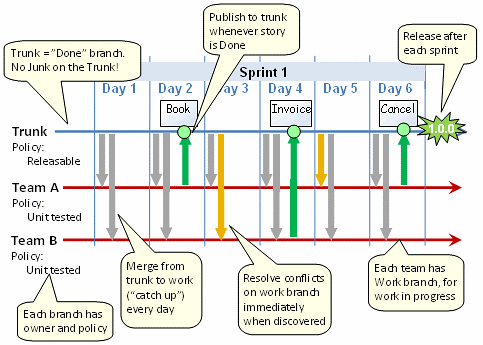
Structure Workflow:
- There will be a Master/Trunk branch, only the code that has to be deployed on production should reside on this branch, if any release is planned for a later stage then that code should not be in this branch.
- Any sub-project or new website/feature should have its own branch, which is created from the master branch.
- Code that is committed to the master branch from any other project branch must be reversed merged into the current project branch.
- So every project will have its own stable branch.
- For internal test deployment on a project basis, tags can be created from the project branch.
- For pre-production and production deployment tag should be created from the Master branch. So same tag will be used to deploy code on pre-production and production.
- For any bugfix or UAT changes after pre-production deployment create a temporary branch from the recently deployed tag and finish the changes and merge that branch into Master, once successfully deployed.
- Once a temporary branch is merged into Master, reverse merge the changes in the project branch.
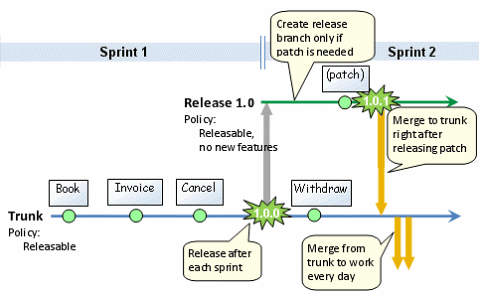
Advantages:
- Avoids creation of multiple branches on the repository.
- Tags created after every release will help in keeping revisions of sprints.
- Every project will have its own stable branch, tags on these branches can also provide revisions.
- Since merging of code from the master branch to project branch has to happen frequently, conflicts can be resolved at an early stage.
- Since the code is merged regularly, testing can be performed on the dev environment at an early stage with the new code on master and currently being developed code.
- This approach will be helpful when multiple teams are working on the same project but are disconnected from each other.
- Any branch that is merged into the main project branch should be deleted once testing is passed.
- Any patch or hotfix branches created from master should also be deleted once merged into master.
- Tags that are created for every revision can be used to create a branch if needed.
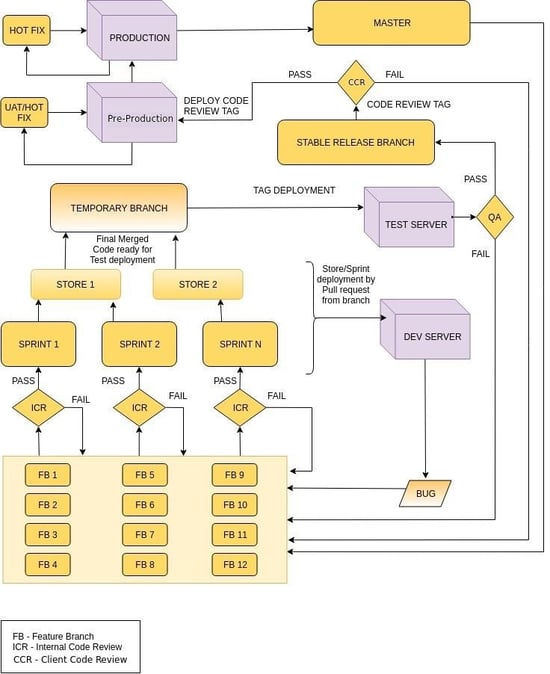
Feature Branch: This architecture of GIT focuses on using Feature Branches of code rather than using a single branch for development of all features, so each feature will have its own branch. All feature branches should be created from the Master branch, this ensures that when a feature branch is created it always has the latest stable code. If a dependency exists between two features, then the dependent feature should be kept on hold until the independent features are not complete. Unit testing and code review will happen on feature branches.
Sprint Branches: All sprints should have a separate branch, this will provide the ease of including of features by sprint and can also be leveraged when the features are included or to be removed at a later stage in a sprint. Any feature branch that has to be merged into a sprint branch has to undergo an (ICR) Internal Code Review before the merge and has to be unit tested too (ICR can be an optional process). This will ensure those code standards are maintained.
If any feature is not to be included in a sprint and is already pulled into that sprint, then discard that sprint branch and create a new branch and merge only particular features which are required in that sprint.
Store/website branch: This can be an optional branch depending upon whether development is parallel for multi-websites or multi-sprints in place. If there is only one sprint and that is being developed for only one website, then the sprint branch can be used instead to create store branches to manage the code.
Sprint branches should be merged in to store branches. These store branches will be stable branches for each respective store.
Deployment on Dev Server: For testing of sprints or stores on an internal dev server code can be deployed by GIT PULL from the sprint or store branch. If any bug is discovered on a Dev server it should be fixed on the feature branch and then again follow the same process to reach the Dev server.
Temporary Deployment Branch: For deploying combined code of all websites together create an empty temporary branch, all the store branches should be merged in this branch and then deploy to Test Server from this branch. If any bugs are reported by the test team fix the bug in the feature branch and follow up the same process. Fixing issues in feature branch ensure that the correct code flows up on all environments.
Stable Release Branch: This branch will always hold a stable code for all combined stores, only the code that has been tested and passed by the QA team should be merged in this branch. Client Code review tag (CCR) should be created from this branch once the latest code has been merged (CCR is again an optional process depending upon client). Same code review tag can then be deployed on further environments such as pre-production, production.
If any code change is to be done after the code review tag is created then it should be implemented from the feature branch itself so that internal code review and testing can be performed and always latest and same code will reside on all servers. This will eliminate the chance of code difference on environments and local setups.
Once the tag is reviewed, deploy to the pre-production environment, if in UAT any minor change is to be done or hotfix needed then create a new branch from current tag and make changes in it and test it, then deploy the tag on pre-production and deploy the same tag on production. Merge the hotfix tag in Stable Release Branch.
Master Branch: The tag that is deployed on production should be merged into the master branch, this ensures that only changes that makeup to production environment resides on the Master branch. Also, the code on master branch is always thoroughly tested on all environments.
Create a tag on master whenever any code is merged, this helps in maintaining releases. If any code is merged to master, the same code should be merged into feature branches. This will help in identifying merge issues or code dependency issues at the development stage. Any merge issues faced on further branches will have to deal with at that point in time.
Actions to be taken after code merged in Master Branch:
- Create tag to maintain versions of the release.
- Delete the feature branches once released to production and tested.
- Delete all temporary release branches if not done already.
- Delete sprint branches since already released.
- Planning of features can be flexible.
- Development of features can be carried out independently.
- No need to create multiple tags for review and for deployment.
- Tag that is reviewed by client architect is deployed on the environment.
- Since all code generates from feature branches same code resides in all environments.
- Any code cannot be missed in tag since tags are created from stable store branches.
- Individual store branches are maintained.
- Stable branch of code for all stores is also maintained.
- A lesser number of branches.
- Tags can be created for features branches and can be used for other projects.