This is the third post in a series of introductory posts intended to help programmers understand Git. These posts are primarily targeted towards Windows using CVS using programmers to help them move to Git for versioning. The previous two posts covered:
- Setup Git on a Windows machine and create the first local repository.
- Create a bare repository and share files with users.
In this post we are going to discuss a few terminologies and dig a little bit deeper (the very reason to write a follow-up post!) in Git.
Let’s begin with a term we know that is ‘branch’. As we’ve seen in the previous post, a branch is a single thread of development and any deviation results in a new branch. We also know that the deviation can be anything- some teams choose to implement every new feature on a new branch that makes fixing and merging to various versions, even backporting very simple. Others choose to develop every module on a new branch and some create new branches for development of newer versions. All are valid and one has to choose what fits best to his/her requirements.
But if we are developing a project in parts, in branches, how are we going to get it all together? May it be a new feature or a new module or a fix, but at some point all that has to merge into one- only then can we have a complete usable code!
Git handles merging rather intelligently. The command ‘git merge’ brings the changes done in one, to the current branch. Simple! Well, almost that simple, unless there happens to be any modifications to the same part of the code in two different branches! Now why would that happen? At times we have to put an existing code inside a condition; a new feature requires a little bit of refactoring and has to be corrected. But then the two branches end up having different code. Let’s not worry with that right now. It’s time to get our hands dirty with some simple stuff first.
Open your Git bash, create a bare repository, and clone it. (We know all this now, don’t we?)
cd d:
mkdir myRemoteRepo.git
cd myRemoteRepo.git
git init --bare
cd ..
mkdir myRepo1
cd myRepo1
git clone /d/myRemoteRepo.git .
Create a new branch. (Oops, my bad, did we see how to create a branch yet? Well, its simple, you just have to say ‘Git branch’ and done)
git branch firstBranch
Failed, didn't it? Well, Git isn’t crazy to create branches for no reason, use the branch you have first mastered! Earlier we discussed that ‘master’ is the default branch, a branch that is created when you initialize a repository, but a new branch can only be created when there is something to create it with - at least a single file - an initial commit that you would work on in the new branch. Let’s create a file that we will be working on in branches.
echo "A generic file which soon will be modified differently in different bra
nches. Why? We are learning, aren't we?" > GenericFile.txt
Nice! You see the file GenericFile.txt created? But how exactly is it created? ‘echo’ is a command that ‘echos’ the string passed to it on the stdout. Here stdout is the Git bash. The next ‘>’ is a redirect operator that redirected the output to a file, GenericFile.txt, and Voila!
Now add and commit the file.
git add GenericFile.txt
git commit -m “A file for creating conflicts.”
Conflicts? We’ll see that, later.
git branch firstBranch
Worked! Worked, Worked! Git has now transferred the current state of the repository as the initial state of the new branch. Whatever we do here on in that branch is not going to affect the files in master branch (diversion!). Notice that the bash reports that we are still on the master branch. Let’s switch branch then.
git checkout firstBranch
Done. Let’s make our first change, add, commit and push all the changes to remote.
echo “a line added from firstBranch in myRepo1” >> GenericFile.txt
Now what? A double redirect? That enters the line twice? Nah, its similar to redirect, but it checks if the file already exists. If it does, it shall append the line passed to it. Effectively, the line we passed should be appended to the file. Check for yourself by opening the file in a text editor and check for yourself. Well, these redirect operators are fun to know but in practice when working with code, you would be using an IDE to make modifications to the code files. For now, they make our job quicker.
git add -u
git commit -m “added a line. no, no conflict yet.”
Time to create our second branch... First switch to master.
git checkout master
Before we create the new branch, open the file GenericFile.txt. Notice something? It doesn’t have the second line we added. Why? That was on another branch, and the changes there don’t affect the state here. Isn’t that awesome?
git checkout -b secondBranch
Yeah, that does both the steps, creates the branch and switches to it. This branch we have ‘branched’ from master, not firstBranch, how is the GenericFile.txt going to look like? Just like it was in master! Let’s try something here now…
git checkout firstBranch
git checkout -b firstBranchChild
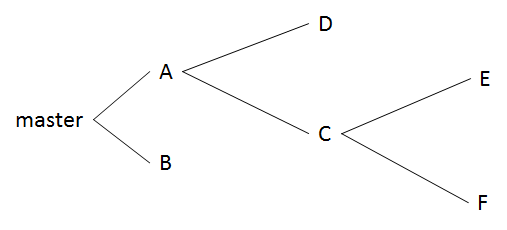
Now how is the GenericFile.txt going to look like here? Just like it was in firstBranch. Let’s try to visualize what the structure would look like if it were plotted:

Now let’s make some changes on firstBranchChild. Add another line and modify the line we added in firstBranch. The total content in the file would be:
A generic file which soon will be modified differently in different branches. Why? We are learning, aren't we?
a line added from firstBranch in myRepo1 and modified in firstBranchChild.
Line added from firstBranchChild.
Commit it and switch to firstChild, there is something interesting there. (Just a reminder: At any point we can check the status by typing ‘git status’.)
git add -u
git commit -m “added a line and modified one, things are about to get interesting now.”
git checkout firstBranch
How would the GenericFile.txt look like? As we left it! This shouldn’t be surprising anymore, that’s what the branches do! Now how would we get the change that we did in the Child branch? That’s where ‘git merge’ comes in. The command picks up the changes done in one branch and updates the files in current branch accordingly. Let’s try it now…
git merge firstBranchChild
And done! Seriously. Check the file! Updated?
In the logs git said something about a ‘fast-forward’. Mark it, we shall see it later.
Let’s go to the ‘secondBranch’ and make a modification to the file. Remember now, the second branch, branches from master and the GenericFile.txt has only 1 line, the first line we added.
git checkout secondBranch
echo “A line we added in Second branch!” >> GenericFile.txt
git add -u
git commit -m “This is it. I dare you to merge.”
Now this is a feature we want to recon in the firstBranch. Consider this scenario: We have two branches of master, first and second. Both branches have the same file modified differently in the same position. This is different from the case of firstBranch and firstBranchChild, where the changes we did are ‘obvious’. There was nothing ‘new’ in firstBranch after the Child branch was created. Let’s see what Git does when we merge the firstBranch and the secondBranch.
git checkout firstBranch
git merge secondBranch
Outputs something like:
CONFLICT (content): Merge conflict in GenericFile.txt
Automatic merge failed; fix conflicts and then commit the result.
That is right. Here, the question would be, assuming these are code files, which is the correct ‘second’ line of code? Git wouldn’t know and it doesn’t want to guess, it’s our code after all. Git explicitly says so and aborts the commit. It also alerts us that the branch is in the state of ‘merging’ by marking it in bash prompt.
Open the txt file. There is something different there, though. Git marks the conflicting content, the file looks like this:
A generic file which soon will be modified differently in different branches. Why? We are learning, aren't we?
<<<<<<< HEAD
a line added from firstBranch in myRepo1 and modified in firstBranchChild.
Line added from firstBranchChild.
=======
A line we added in Second branch!
>>>>>>> secondBranch
No, those of course are not ‘append append append’ redirects. The latest commit in the current branch is always nicknamed as “HEAD”, the direction in which the branch grows. “>>>> secondBranch” is the indicator that the conflicting content from the ‘merged’ repository ends, which started after the separator. What Git is trying to say here is: See, you have modified an area of the file in a way that I am unable to confidently choose one modification over the other, so here are both, choose for yourself. And that’s what we do. We modify the file, keep the change we want, ‘remove the markers’ (Important!) and commit the file.
git add -u
git commit -m “Yeah, resolved the conflict. Piece of cake.”
A question though arises- if there were multiple commits to both branches, multiple merges from other branches, from where should a change be considered as a ‘deviation’ for marking in conflict? Interesting, isn’t it? There’s some logic to that. We shall see that in my follow up post, and also the fast-forward.
Also a quick tip, I am getting tired of typing ‘git add’, ‘git commit’, ‘git checkout’ and the like repeatedly, aren’t you?...stay tuned in!