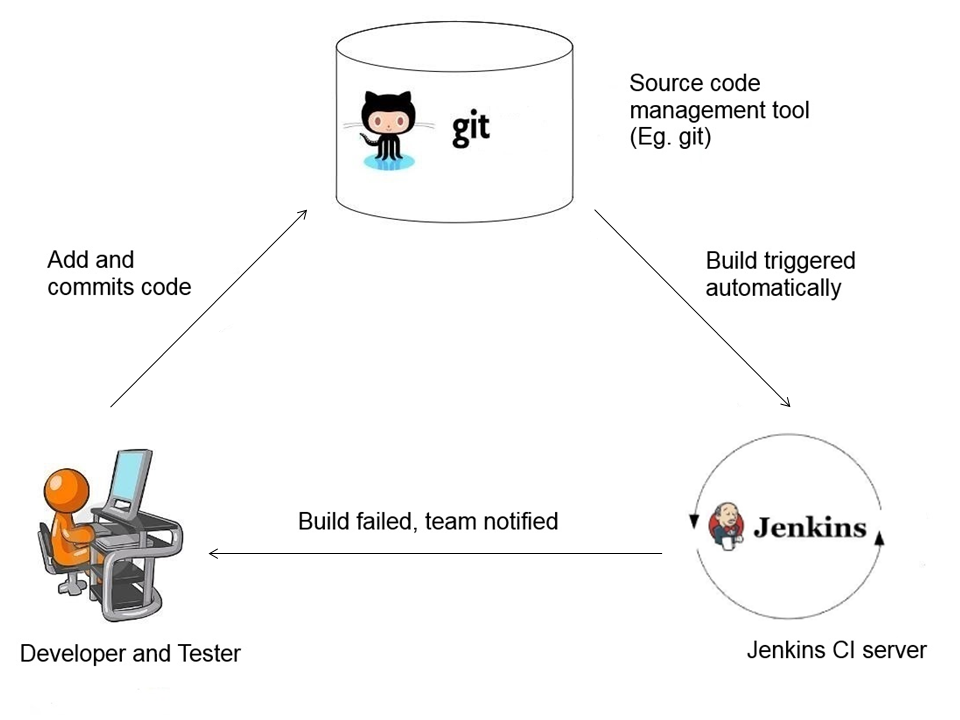
Version control is one of the most critical aspects of software development and Git is one of the most popular versioning software! Version control comes under Software Configuration Management which in simple terms means tracking and maintaining a history of changes done to our source files.
Before we jump into further details, let me first clarify that this post is primarily targeted at users coming from CVS and using Windows machines. It is intended for easing the shift of developers from using CVS to Git. So we shall also be seeing some of the basics of bash and comparisons with workflow for CVS.
Git (pronounced as [git] not [jit], as per Linus) is a distributed version control system originally designed by Linus Torvalds for the development of Linux kernel. Distributed, unlike centralized, means that there is no server-client model, each user gets a copy and each user’s copy is a full repository! Communication between two such copies/repositories happens through a common remote repository to which the users can sync their copies.
For those coming from CVS background, or any centralized versioning system for that matter; the aspect is a little different and may seem cumbersome in the beginning. Their workflow has always only been syncing with a single central server where everyone copied files from to a working directory, worked on the file and sent the file back to the server. And in large organizations and projects, they would also be used to request a configuration controller for creating a branch, checking differences and merging branches.
Here in this distributed versioning land though, everyone gets their own copy of the repository, with complete control over it. And we also keep our working directory in the same folder as your repository, yes we do, normally. A central location normally only shares a ‘bare’, repository-a folder containing only the metadata, not the actual files, i.e. ‘no working directory’. For every change we make we need not reach out to the server or a configuration controller, it’s our copy of the repository after all! Of course, for modifying the copy at the central location we would still need approvals. But hey, it’s not like we can connect to only one remote repository!
Remote repositories tend to be bare; no working directories are expected to be on sharing servers. The repositories we clone from these or normally initialize on our local system have working directories in them (For convenience sake, let’s call them ‘local’ repositories).Although, there is a way to split a ‘local’ repository into two separate folders-one containing the bare and the other working directory, it really is a pro tip for the later. Besides Git, GUI for windows is not good at handling bare repositories.
Now we shall set up Git, initialize a repository and add our first file to it. For this post, we shall not be creating a bare repository; we shall see the full workflow in a following post. A warning-Git assumes a Linux like file system, although it is running on windows, there are some subtle differences in its behavior. We shall discuss them as and when they are relevant.
To set up Git, download and install Git from http://git-scm.com/download/win. The version for windows is called ‘msysgit’. During installation, we can choose to enable Windows Explorer context menu integration. The cheetah plugin is known to have some issues and I would advise you against using it for now.

On the next screen, we can choose the second option to allow Git command to be added on to our path.

On the next screen, since all our users are going to use Windows, it is safe to choose the first, “Checkout windows style and commit Unix style line endings option”. Although, enabling autocrlf sometimes confuses even the Git status command (we will see what it is in a while), if there is a mix of line endings. But since all users are using a Windows machine, it should not be a problem.

Well, let’s see how a Git repository is like and how to create one,
A Git ‘bare’ repository is a folder containing only the versioning data, no working directory, and no files. These repositories are normally used as ‘remote’ when sharing changes between users.
Whereas, a regular Git repository will have both a ‘.git’ folder that holds all the versioning metadata and outside which is our working directory. Why dot (.)? It marks a directory as hidden in Linux based OS, i.e. .git is intended to be a hidden directory although we are able to see it in Windows.
So let us begin.
Go to programs → git → git bash.
This should open a colorful terminal (command line) for us. Although we can run git directly from command prompt (cmd) the bash is where we will learn to work. There is no difference in the commands or otherwise in running Git from command prompt.
Let’s switch to D drive and create a new folder to contain our project. So type:
cd D:
mkdir myFirstProject
cd myFirstProject
Did you notice that although we typed ‘D:’ it’s showing us the current directory as ‘/d/’. What’s with that? Let’s see a little bit about linux file systems and path separators: In linux based OS, file system is like a Tree, everything stems from one root. There is a single folder referred to as ‘root’ (surprised?) and every single thing, including devices attached to the computer are represented as files/directories. (Directories themselves are files too, imagine a telephone directory!) This root is denoted by a forward slash: “/”. In windows there is no single root, there are multiple drives (roots). To simulate this in linux like file system, the drives are assumed as directories, hence, /d/. And yes, the path separator here is a forward slash (/) unlike Windows which uses backslash (\) instead.
Also, there is no ‘md’ command here; we use mkdir instead, which does the same thing.
Now that we are in the folder, let’s add our first file. There is typical linux method of creating a file, a command called ‘touch’, but let’s not touch that, open Windows Explorer, navigate to myFirstProject and create a text file called “FirstFile.txt”. We are going to add versioning for this file.
Back in Git Bash:
git
Hold on, who are you again? Git might ask we never introduced ourselves! Bad manners!! Let us then:
git config --global user.name "Nikhil Wanpal"
git config --global user.email "nikhil_wanpal2@ezest.in"
Here with --global flag we are saying that use these details for all repositories unless I specify it differently. When we type the same command, but without the --global flag, we are saving the settings particularly for the repository we are working in. (No spammers, this is not the email Id you are looking for! :)) Now that git knows us:
git init
Now that should add the .git folder and with that, we have created a repository. Simple!! But what is in it? Is there anything we should commit? Our best friend when working on git is:
git status
This command tells us a lot about the repository: That we are currently on ‘master’ branch, if our local repository differs from origin (branch? origin? Rest Neo, the answers are coming.) And by how many commits, if there are any files that are modified and also if there are files in our working directory that git doesn’t yet know about. (Untracked files). Under this is where we shall see our FirstFile.txt. Now let’s tell git about it:
git add FirstFile.txt
Git bash is context aware, typing ‘fir’ and hitting tab should complete the filename for us. And for the sake of Windows user’s it also neglects the case.
What we are saying here is: “Hey git, you know this file FirstFile.txt? I would like to have a versioning for this; can you please add the file for versioning?”
Git says ‘Yes, why not!’
This step is new for the CVS folks, this is not ‘commit’ you see, this is just ‘add’. Like marking the file it’s actually called ‘staging’.
Now let’s introspect a little, let’s see how we really work: For implementing a given functionality we normally modify more than one file, it happens most of the times. May it be a related config file, a constants file a new command or a service or DAO, or anything but rarely are the changes limited to a single file. In a CVS repository, we can commit multiple files by using command like cvs commit file1 … fileN, or just cvs commit, but in either case identifying a patch later is not that easy. Git is all about changes; it lets us choose which all modified files from the working directory should be committed, as a group. Every commit is treated as a group commit, and we are required to identify files for it. Also understand that even adding to ‘staging area’ is treated like a version, any change made to the file after it was added to the staging area must again be added with the add command.
The next step is the familiar commit:
git commit -m “Initial commit”
And done, we have committed our first file in our git repository. Let’s verify the same, that there is nothing to commit, by typing:
git status
With the -m flag, we are passing an inline comment for the commit. If the flag is not added, git opens up a VI editor instance, where we can add the commit comments. If the change is large, involves many files, it is good to etch out each detail in using an editor that crunches everything in a single string.
Now that we know the basics, we shall look at the little more advanced stuff soon.