

While working on small or moderate data sets, aggregation feature is measured as the best viable option. This is because, aggregation can be performed with help of a small standard query which is efficient and simple to use. But, can aggregate feature work well with large data sets? The answer is ‘NO’. Aggregate features won’t work with large data sets, as the query execution will devour extra time in terms retrieving huge amount data and eventually slow down application’s performance.
Within smaller data sets fetching and comparing values from particular column or rows is easier as compared to large data sets. But, what solution can be offered to deal with large data sets, wherein PostgreSQL can just return the records without hampering system performance and additional efforts.
To save the application from slowing it is performance, indexes can be used. But a superior option is rollup tables. They can be used instead of large primary data sets because it is capable of executing multiple conditions in combination. So, if your table has huge amount of records, directing your queries to a small roll up table would be feasible, as a small table might have all the pre-aggregated values for the conditions you might need to fetch data for.
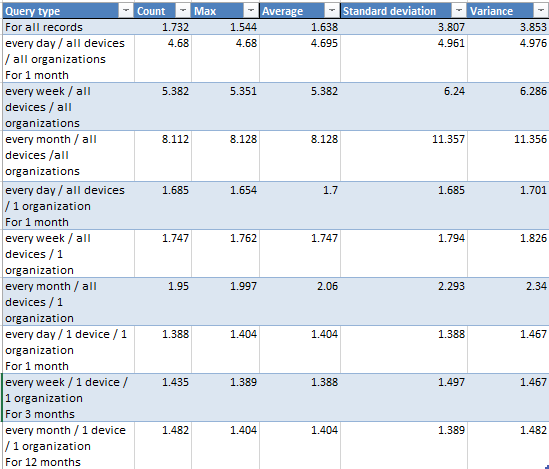
Here is an example, where we are fetching 10885,500 temperature records of 12 organizations with 30,000 devices. The processor we have used is Intel Core i3 3220 and RAM is 8 GB. So in this case, if we execute the query on the fly using large data sets then the time consumed to display results would be too much. Check below table and details where query execution time is mentioned in seconds.
- Each device sends one record per day.
- We are showing change in temperature over one year.
- We will calculate min, max, avg, and std deviation which in a way defines change.
So what can be done to keep the data in sync?
- Full recalc: Recalculate all of your rollup values, once you are done with updating your data in source table. To recalculate you can query source table and GROUP BY rollup columns. After this, PostgreSQL will loop entire source records and retort with updated values which then can be used to write to your roll-up table. Full recalc can be an effective method through which you can sync your data, irrespective of what you alter in your source data table.
- Per-entry update: Using PostgreSQL to recalculate entire rollup values can be an exhausting. Still, if we are aware of what change we need to make, that can be a simple, as we can update those specific rollup values easily. So, instead of recalculating values, we can maximize the rollup value with 1. The other rollup values can stay as it is.
Though, per-entry update requires extra efforts as compared to full recalc, it can be done generically. With every single update to source table, the changes to rollup table can be reduced. All we have to do is perform 1 read query to the source table before we update data and later 1. This will provide us with real updated values and also provide the information on which rollup values requires to be updated. - Periodic calculation job: This solution is the most efficient one. There are some cases where full recalc or per-entry update might not work or would require full data sets to process it. Hence in this case, periodic calculation can work. This solution might not immediately provide with data sync, but with a programming logic we can make it work.