Introduction:
Text searching is one of the key implicit requirements of most of the web applications. Text searching has lot more to do than just searching the database with %searchText% type query. If your web application holds lot of text data and you want to the user to dig into this and get the meaningful result, then mere sql search is very trivial option in the era where people knows about Google Search. Mere text search with sql statement has lot of limitations like the few one listed below.
- Exact text must match. User must enter correct word to search window.
- If in database there is text "gigabyte" and you search for “GB” then although “GB” is short form of "gigabyte" you will not get the desired search output.
- In hurry you tend to make spelling mistake when entering search criteria. The suggestion of correct spelling is not possible (in straight forward way) in normal database search.</li.
- Sounds like search is difficult to achieve in normal database search. For example if I enter word "found" then in response if I would like to search the documents which has words like "sound", "bound" etc which sounds like "found" is difficult to achieve.
Solr is not replacement for database to store data related to text searching. But if you want to overcome the limitation imposed by sql search, then welcome to solr.
Few website which uses Solr
- http://www.whitehouse.gov/ - Uses Solr via Drupal for site search w/highlighting & faceting (More details: 1) Instagram a Facebook company, uses Solr to power its geo-search API.
- FCC.gov is the new FCC website featuring Solr powered search and faceted navigation. Comcast / xfinity uses Solr to power site search and faceted navigation.
- AT&T Interactive uses Solr to run local search at yp.com, the new yellowpages.com
Source: (http://wiki.apache.org/solr/PublicServers)
Sounds similar to Lucene:
Yes, basically solr is build on the top of lucene. It’s a production ready well tested search server with additional features lik
- XML/HTTP,JSON APIs
- Keyword highlighting
- Faceted search
- Caching for faster searching
- Web administration interface
Solr performs very well when querying on already indexed data. But if your application requires concurrent indexing and querying the data then probably elasticssearch is better option.(http://www.elasticsearch.org/) (http://engineering.socialcast.com/2011/05/realtime-search-solr-vs-elasticsearch/)
Solr can extract data from many different sources like PDF, Office, Binary files, database, text files then index the text content and based on the query returns the response in many different format like json, xml, csv, php.
Solr comes in 2 flavors. First is as a web application which you can deploy on any application server and second is as embedded solr. Embedding Solr is less flexible and not as well tested and it use is reserved for special circumstances.(http://wiki.apache.org/solr/EmbeddedSolr).
Helpful Tools and Utilities:
- CURL: http://curl.haxx.se/dlwiz/ a command line tool to post documents to Solr
- LUKE: http://code.google.com/p/luke/ utility to view and analyse index created by solr
- TIKA: http://tika.apache.org/ a content extraction library which extract the content from various file types(pdf,world.xls, zip, tar, jar, mp3, bmp etc). The extracted text content can be feed to solr and then solr can index those documents. Using solr query user can search various attributes which tika has extracted from variety of files.
Following figure shows how solr stores data:

Whenever the document is uploaded to solr either by using SolrJ (Java APIs for solr) or CURL or any other way, generally it goes through following process.
The request is intercepted first by analyzer. Analyzers pre-process the input text. Analyzer consists of a Tokenizer and one or more TokenFilters. Tokenizer splits the text content, for example Solr WhitespaceTokenizer splits the incoming text at white space. Then this tokenized data is passed to series of filters. These filters applies various formatting to tokens like changing case, stemming( changing the word to its root level for example word like documents, documenting will be changed to document), removing special characters/syntax (removing html/xml tags) etc.
Then these tokens are processed by solr core (lucene) and then indexed.
Note: The analyzer which is used for uploading the data, same analyzer has to be used to query the data. Otherwise you will not get expected result.
Architecture:
There are two main files used in solr configuration
A) schema.xml: Use to define the datastructue or the format in which solr will store the data
This file contains the metadata, the table structure kind of thing in which solr will store indexed data It has following components
"type": is the root element of the schema which contains "fieldType" definition, field types are basically type of data(int, float, string, binary etc) which is further used when you define fields in schema. In addition to basic data type you can configure the fieldtype with analyzer, tokenizer, filters. So using this configuration you can manage the data which gets stored in the field having this fieldtype
Example:
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Here text_general is the name of fieldType. Its implementation is provided by solr.TextField class. positionIncrementGap attribute is basically used for multi valued field. For example if you are accepting multiple phone number from user no1 is 12345 and other is 67890 and both of these are stored in the same fieldType for the same document and positionIncrementGap is 0 then query for phone no 45678 will also match this record. So here positionIncrementGap=100 will put the gap of 100 between 12345 and 67890, preventing false phrase matching.
In the above example analyzer and filters are configured for indexing as well as querying. For details about various attributes refer to the schema.xml file itself. It is very well documented.
Fields are actually like columns in a table. These fields can be customised base on the need of project. The data stored in field can be of any type which is defined in "fieldType" element.
Example:
<field name="name" type="text_general" indexed="true" stored="true"/>
stored=true will store the actual value of incoming text.
Solr schema has one interesting element called dynamic field. So it is just like defining the database column at run time. So at the time of defining solr schema, if you are not sure about what are the columns needed then dynamic field will provide great help.
"uniqueKey" element is like primary key to index the document. Using this "uniqueKey" the document can be referred later and modified.
"copyField" is another interesting element. It is used to copy one column data to other. So for example for a PDF document there is title, subject and actual text content. Now you have provided the search PDF functionality on your website and you want it to be flexible, so you don't want user to specify that whether he want to search the entered text in title field or subject field or actual content. So in this case you can use copyField to copy title and subject to actual content, and let the user query only "content" column.
B) solrconfig.xml: Use to fine tune and configure solr. Use can set the caching properties, ram size like properties in this file, configure the URL which are used by solr.
Request Handler configuration.. The request intercepted by solr can be configured in this xml element.
Following examples shows request handler for /select. So when the user hit the url http://localhost:8983/solr/select?q=doc this request handler will come into picture.
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">text</str>
</lst>
</requestHandler>
You can specify the default request handler parameters. In the below example 3 defaults are specified. echoParams(displays the input params), rows(max rows returned by query, 10 in this case), df(default index column to search for, in this case it is "text" column)
These default values can be overridden by specifying query params.
http://localhost:8983/solr/select?q=doc1
is same as
http://localhost:8983/solr/select?q=text:doc1
overriding default seach field
http://localhost:8983/solr/select?q=price:10
here the value 10 is searched in price column instead of text
Basic solr operations
After you download solr release, unzip it and goto example directory and run the command
java -jar start.jar
This will start Jetty server, which comes by default with solr.
Following example shows various operation which you can perform using SolrJ.
Changes in schema.xml (in folder examplesolrconf)
Modify text_general fieldType to include stem filter.
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" enablePositionIncrements="true" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Add field to save language specific data.
<field name="text_hi" type="text_hi" indexed="true" stored="true"/>
SolrJ Example:
package com;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServer;
import org.apache.solr.client.solrj.impl.CommonsHttpSolrServer;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
public class SolrExample {
public static void main(String[] args) throws Exception{
SolrServer server = null;
try
{
server = new CommonsHttpSolrServer("http://localhost:8983/solr/");
}
catch(Exception e)
{
e.printStackTrace();
}
//Delete all previously created indexes.
server.deleteByQuery( "*:*" );
//books
SolrInputDocument doc1 = new SolrInputDocument();
doc1.addField( "id", "id1", 1.0f ); //unique id of the document
doc1.addField( "name", "Solr 1.4", 1.0f );//name of book
doc1.addField( "price", 50 );//price
SolrInputDocument doc2 = new SolrInputDocument();
doc2.addField( "id", "id2", 1.0f );
doc2.addField( "name", "Solr cookbook", 1.0f );
doc2.addField( "price", 20 );
SolrInputDocument doc3 = new SolrInputDocument();
doc3.addField( "id", "id3", 1.0f );
doc3.addField( "name", "Wings Of Fire", 1.0f );
doc3.addField( "price", 40 );
SolrInputDocument doc4 = new SolrInputDocument();
doc4.addField( "id", "id4", 1.0f );
doc4.addField( "name", "Science Of Sound", 1.0f );
doc4.addField( "price", 30 );
//general data
SolrInputDocument doc5 = new SolrInputDocument();
doc5.addField( "id", "id5", 1.0f );
doc5.addField( "name", "8 Gigabyte Ram specification", 1.0f );
doc5.addField( "price", 30 );
SolrInputDocument doc_hi = new SolrInputDocument();
doc_hi.addField( "id", "id_hi", 1.0f );
doc_hi.addField( "text_hi", "साईनाचा संघर्षपूर्ण विजय", 1.0f );
/* Uploading documents to solr server and committing it*/
Collection docs = new ArrayList();
docs.add( doc1);
docs.add( doc2);
docs.add( doc3);
docs.add( doc4);
docs.add( doc5);
docs.add( doc_hi );
server.add( docs );
server.commit();
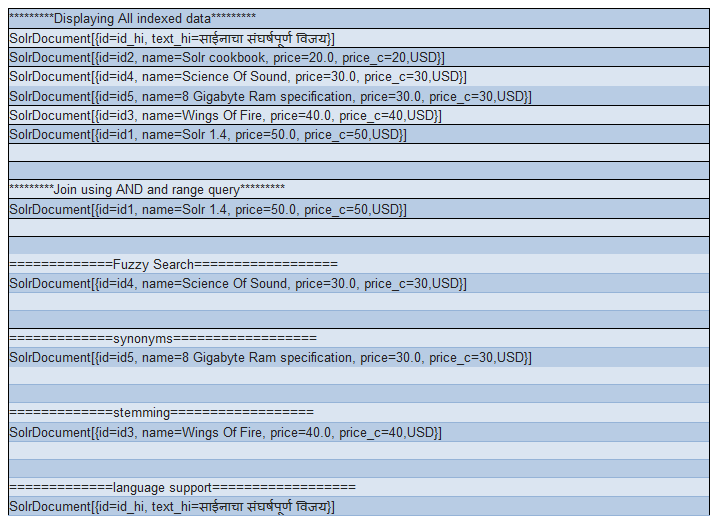
System.out.println("*********Displaying All indexed data*********");
SolrQuery query = new SolrQuery();
query.setQuery( "*:*" );
query.addSortField( "price", SolrQuery.ORDER.asc );
QueryResponse rsp = server.query( query );
SolrDocumentList docsOutupt = rsp.getResults();
Iterator itr = docsOutupt.iterator();
while(itr.hasNext()){
System.out.println(itr.next());
}
System.out.println("n");
System.out.println("*********Join using AND and range query*********");
query = new SolrQuery();
query.setQuery( "name:solr AND price:[35 TO 55]" );
query.addSortField( "price", SolrQuery.ORDER.asc );
rsp = server.query( query );
docsOutupt = rsp.getResults();
itr = docsOutupt.iterator();
while(itr.hasNext()){
System.out.println(itr.next());
}
System.out.println("n");
System.out.println("=============Fuzzy Search==================");
query = new SolrQuery();
query.setQuery( "name:found~" );
query.addSortField( "price", SolrQuery.ORDER.asc );
rsp = server.query( query );
docsOutupt = rsp.getResults();
itr = docsOutupt.iterator();
while(itr.hasNext()){
System.out.println(itr.next());
}
System.out.println("n");
System.out.println("=============synonyms==================");
query = new SolrQuery();
query.setQuery( "name:gb" );
rsp = server.query( query );
docsOutupt = rsp.getResults();
itr = docsOutupt.iterator();
while(itr.hasNext()){
System.out.println(itr.next());
}
System.out.println("n");
System.out.println("=============stemming==================");
query = new SolrQuery();
query.setQuery( "name:Wing" );
query.addSortField( "price", SolrQuery.ORDER.asc );
rsp = server.query( query );
docsOutupt = rsp.getResults();
itr = docsOutupt.iterator();
while(itr.hasNext()){
System.out.println(itr.next());
}
System.out.println("n");
System.out.println("=============language support==================");
query = new SolrQuery();
query.setQuery( "text_hi:?????*" );
rsp = server.query( query );
docsOutupt = rsp.getResults();
itr = docsOutupt.iterator();
while(itr.hasNext()){
System.out.println(itr.next());
}
}
}
Output of Program: