Amazon Redshift provides an extensive framework to analyze our petabyte scale data with optimized cost with our existing BI tools. Redshift provides a cost effective, scalable, secure and fast analysis framework for our large data sets.
With Just $1,000 per terabyte per year i.e. 1/10th cost of most of traditional data warehousing solutions, it is optimized for datasets ranging from few hundreds GB to petabyte scale of data.
Amazon Redshift delivers fast query and I/O optimized performance for virtually any size dataset by using columnar storage technology and parallelizing and distributing queries across multiple nodes.
Virtually for any size large data sets by its columnar data storage and fast parallel processing the queries by distributing them across multiple nodes the solution offer the best approach for large datasets analysis.
In comparison with its competitor Hadoop + Hive, the Redshift provides a scale up in performance by 10X and cost reduction by about 10 times over Hadoop + Hive.
Besides its cost efficient and reliable output this Postgre solution minimizes the efforts of programmer as the normal SQL queries work with minimal changes.
Amazon Redshift uses industry standard ODBC and JDBC connections and Postgre drivers.
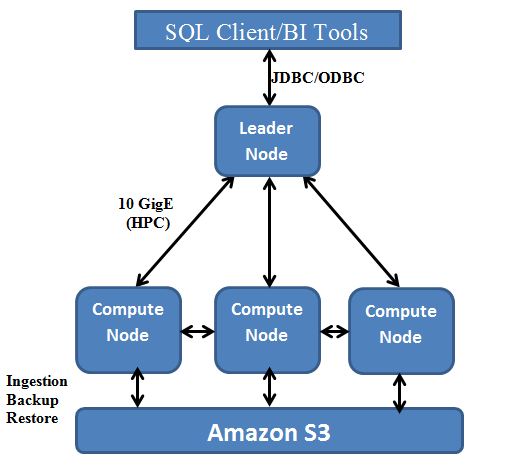
A Peep in to Redshift
Architectural Components of Redshift
Cluster: Cluster is a core infrastructure component of an Amazon Redshift data warehouse that is provisioned with two or more compute nodes.
Leader node: Leader Node coordinate compute nodes and handles external communication.
The leader node manages communications with client programs and all communication with compute nodes.
Compute Nodes: The Leader node assigns the tasks or distributes the task to the compute nodes. The compute nodes execute the compiled code and the send intermediate results back to the leader node for final aggregation.
Node Slices: At the Node Slices the query is split across multiple threads and even multiple systems, similar to the way that Hadoop processes a MapReduce job.
Keys in tables define how the data is split across slices. Data is split based upon commonly-joined columns, so that joined data resides on the same slice, thus avoiding the need to move data between systems.
Presorted Data enables faster querying when ranges of data are used, such as date ranges or ID ranges. Very similar to Partitioning Technique in traditional Databases.
Redshift provides Backup of all your data
Redshift provides with automated backups of all your data. All data includes all data blocks, system metadata, partial results from queries and backups are stored in S3. Each data block gets its own unique randomly generated key. These keys are further encrypted with a randomly generated cluster-specific key that is encrypted and stored off-cluster, outside the AWS network, and only kept in-memory on the cluster
Security Offering of Redshift
As a managed service, Amazon Redshift builds on this foundation by automatically configuring multiple firewalls, known as security groups, to control access to customer data warehouse clusters.
Customers have explicit control to set up ingress and egress rules or place their SQL endpoint inside their own VPC, isolating it from the rest of the AWS cloud.
For multi-node clusters, the nodes storing customer data are isolated in their own security group, preventing direct access by the customer or the rest of the AWS network.
Easy integration with existing Amazon AWS services
Comparison with Hadoop:
Consider Redshift:
Consider Hadoop:
With significant cost saving, efficient and reliable solution, Amazon Redshift has made a petabyte data analysis a game of minutes.
{kind=link}
{kind=link}